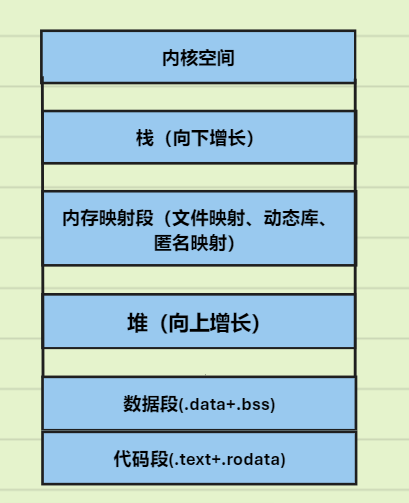
C++中的进程虚拟内存布局
进程虚拟内存布局
进程虚拟内存布局:
.text(代码段):存放的是程序源代码编译后的机器指令,是只读的。
.rodata(只读数据段):存放的是程序中的只读数据,一般是程序里面的只读变量和字符串常量。
.data(数据段):存放的是已经初始化了的全局静态变量和局部静态变量
.bss:存放的是未初始化的全局静态变量和局部静态变量
堆:一般由程序员分配释放,若程序员不释放,存放一些new创建出来的对象
栈:由编译器自动分配释放,存放函数的参数值,局部变量的值等
内核空间:是OS内存管理的一部分,用于存储和运行操作系统内核的代码和数据
生命周期:
- 代码段:在程序加载到内存时被分配,并在程序结束时释放
- 数据段:与程序生命周期相同
- 堆:堆上的内存需要在运行时手动分配和释放,如果不手动释放,堆上内存在程序结束时,由系统释放
- 栈:离开它的作用域后由系统释放
栈和堆的区别:
- 内存分配方式不同:
- 栈:栈上的内存是自动分配和释放的,通常用于存储函数调用过程中的局部变量、调用参数和使用的寄存器状态等信息。
- 堆:堆上的内存是动态分配的,程序在运行时可以根据需要分配和释放内存。在C++中可以通过new/new[]分配堆内存,使用delete/delete[]释放堆内存。在C中可以使用malloc、calloc和realloc函数分配堆内存,使用free函数释放堆内存
- 生命周期不同:
- 栈:栈上的内存生命周期与函数调用相关。局部变量在函数被调用时自动分配内存,函数返回时自动释放内存
- 堆:堆上内存的生命周期取决于程序员手动分配和释放。分配的内存在程序运行过程中移植存在,直到被显式释放或程序结束
- 内存管理不同:
- 栈:栈上的内存由操作系统和编译器自动管理
- 堆:堆上的内存需要程序员手动管理。可能导致错误,如内存泄露、野指针、重复释放等
- 内存大小不同:
- 栈:栈的大小相对较小,适用于存储较小的数据结构和对象。分配和释放栈内存的操作非常快速,但栈空间有限,可能导致栈溢出错误
- 堆:堆的大小通常比栈大得多,因此可以用于存储较大的数据结构和对象。然而,分配和释放堆内存的操作相对较慢,可能导致程序性能下降
可执行文件和进程虚拟内存布局:
可执行文件中存在 .text、.rodata和.data,不存在.bss、堆和栈。因为.bss上的内存是在可执行文件中存储未初始化的全局变量和静态变量的内存区域,为了节省空间,在程序加载到内存时,.bss段中的变量会被自动初始化为0或空指针,所以不占用任何空间。而栈和堆是在程序运行时分配的。
为什么要把程序的指令和数据分开?
- 出于保护只读区域的原因:数据区域堆进程来说是可读写的,而指令是只读的
- 对于现代CPU来说:现代CPU的缓存一般都设计成指令缓存和数据缓存,指令和数据分开有利于提高程序的局部性,有助于提高CPU缓存命中率
- 从共享的角度:程序中运行多个程序时,使用的指令是一样的,内存只用保存一份,将指令和数据分开,可以使指令共享,节省资源。
栈何时会溢出?(栈的大小是可以修改的)
- 递归调用层数过深
- 局部变量占用过多空间:一个函数中声明了过多的局部变量,或者某个局部变量占用的内存空间过大时,会导致栈空间快速耗尽
- 大量函数调用嵌套:如果程序中存在大量的函数调用嵌套,而栈空间不足以容纳所有的函数调用信息,也会导致栈溢出。
栈和堆分别存放着什么?
- 栈:函数返回地址、调用参数、局部变量以及使用的寄存器状态等信息
- 堆:程序运行时使用new,malloc等动态分配的内存
C++中的进程虚拟内存布局
http://example.com/2024/12/20/C-中的进程虚拟内存布局/