为什么要内存对齐
内存对齐
初步认识
内存对齐是什么?从下面的代码可以比较直观地有一个简单的认识:
1 | |
上面的代码输出如下:
- s1为8字节:
- i:4字节
- c1:1字节
- c2:1字节+2填充字节
- s2为12字节:
- c1:1字节+3填充字节
- i:4字节
- c2:1字节+3填充字节
- s3为8字节:
- c1:1字节
- c2:1字节+2填充字节
- i:4字节
原因探究
简单来看,主要是以下两个原因:
- 性能优化:大多数现代处理器都要求数据按照特定的边界对齐,因为寄存器只能从能整除以4的地址开始读取数据(一次读取4字节(32位)或8字节(64位)),为什么寄存器这样设计,也是为了能够并行处理,加快内存访问。
- 硬件要求:某些处理器对于未对齐的/内存访问是禁止的,可能导致错误
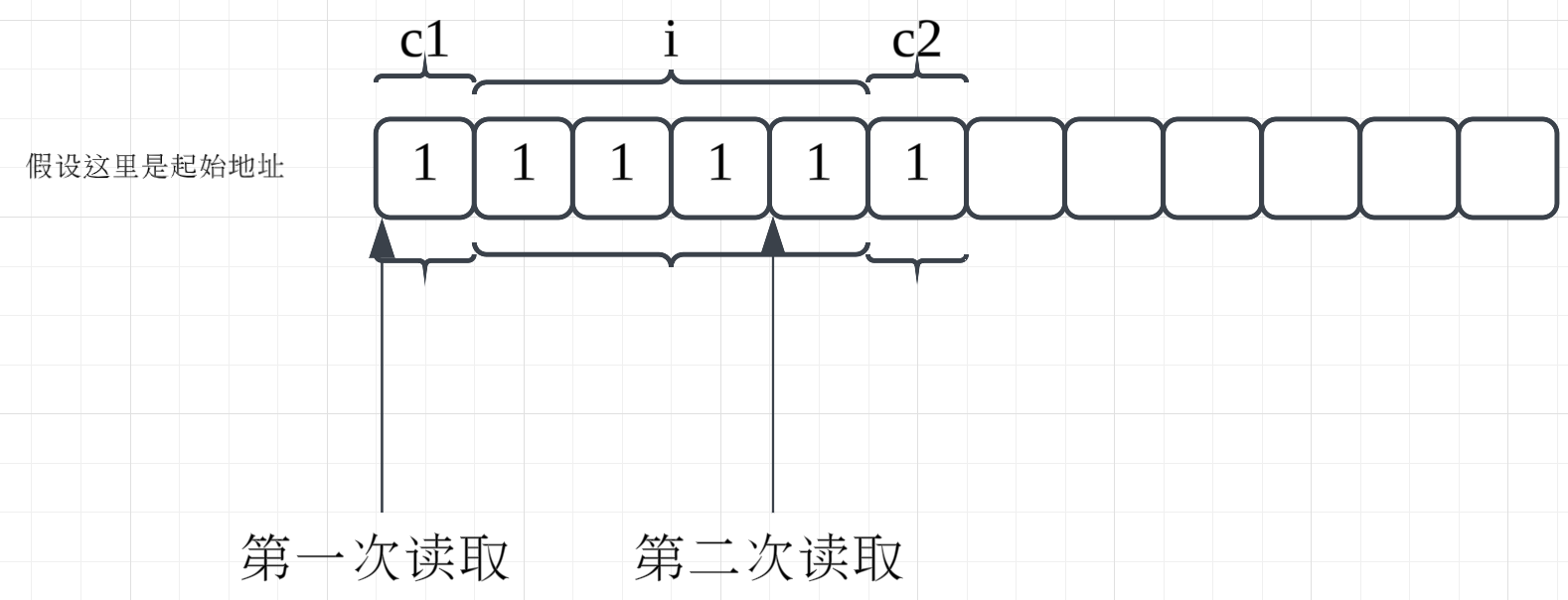
我们主要研究第一个原因性能优化,就拿上面的代码中的结构体s2来说,如果内存没有对齐,假设内存是如下分布的:
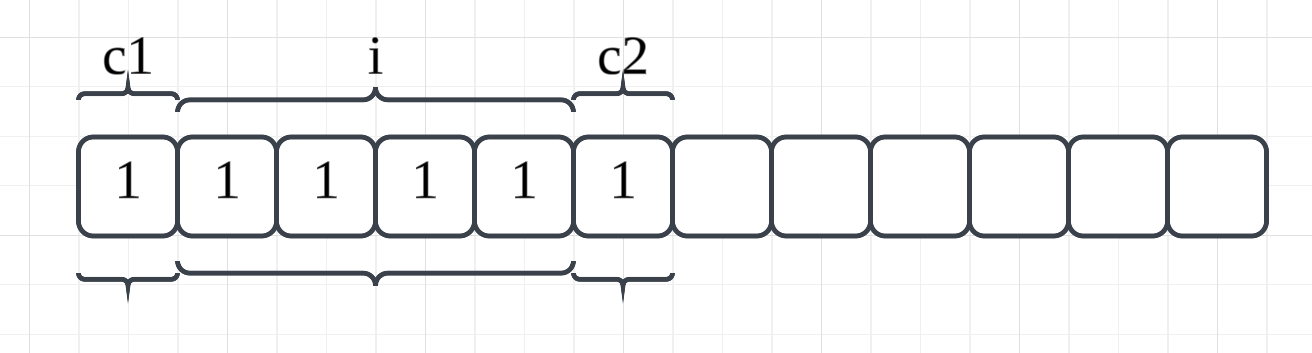
如果要读取变量i,就需要进行两次读取操作,然后再获取到变量i的值
如果内存是对齐的,则内存如下分布: 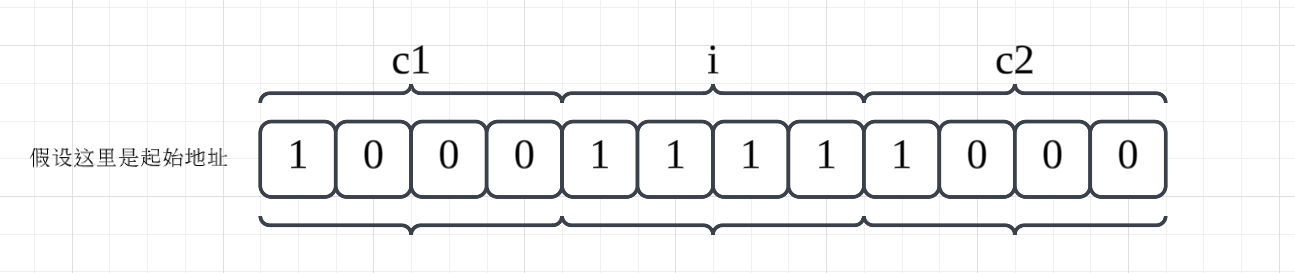
如果要读取变量i,只需要进行一次读取操作: 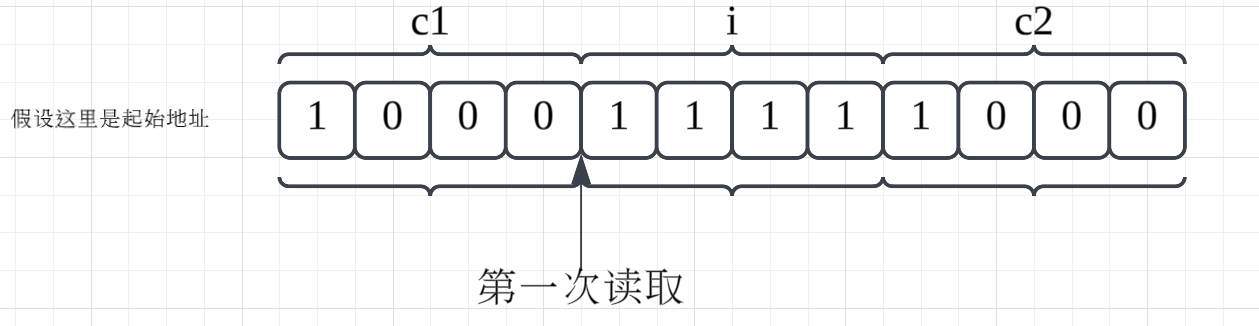
所以可以看出,内存对齐是真的可以加快内存的访问,提高性能。
口头回答: 为什么内存不对齐,就有可能导致额外的读取操作?(读取6字节数据和8字节数据,为什么读取8字节的性能就更高?)
因为寄存器只能从能整除以4的地址开始读取,也就是内存地址被一个一个的边界进行”分割“,且寄存器只能从这一个一个边界开始读取数据,内存不对齐有可能导致数据的存放刚好被边界分成两边,这样就得读取边界的左边和右边,才能把这个数据读取完整。
取消内存对齐
这里主要讨论在C/C++中,如果对结构体取消默认的内存对齐
使用#pragma pack指令:
1 | |
使用alignas关键字: C++11引入,然而,alignas只能用于增加对齐要求,不能用于减少对齐要求,因此无法通过alignas取消内存对齐
1 | |
为什么要内存对齐
http://example.com/2025/01/19/为什么要内存对齐/